服务网格架构下的大语言模型系统设计
随着人工智能技术的快速发展,大语言模型(LLM)正在各行各业得到广泛应用。然而,在构建生产级LLM服务时,开发者面临着诸多挑战:高可用性、弹性扩展、请求路由、负载均衡以及容灾等。本文将探讨如何利用服务网格架构构建微服务化LLM系统,为企业级AI应用提供可靠、高效、灵活的基础设施。
服务网格(Service Mesh)定义:
服务网格是一个专用的基础设施层,用于处理服务到服务之间通信,在微服务架构中实现可靠的请求传递,同时提供零信任安全、可观测性和高级流量管理能力。

图1: 服务网格架构概览
核心概念
服务网格与微服务架构
服务网格是专为微服务架构设计的通信基础设施层。在传统微服务架构中,服务间通信逻辑通常嵌入在应用代码中;而服务网格将这些通信逻辑迁移到独立的基础设施层,通过边车代理(Sidecar Proxy)模式实现,使应用开发人员能够专注于业务逻辑。
服务网格的主要组件
- 数据平面:由一系列以边车模式部署的轻量级网络代理组成,负责处理服务之间的通信。
- 控制平面:管理和配置数据平面代理,提供API进行策略设置和获取指标。
- 边车代理(Sidecar):与服务实例并行部署的网络代理,拦截进出服务的所有网络通信。
LLM系统的特殊需求
大语言模型系统相比传统微服务有一些特殊需求:
计算资源密集型
LLM推理需要大量GPU资源,资源利用率和调度至关重要。
请求处理时间差异大
不同长度和复杂度的输入会导致处理时间差异巨大。
高可用性要求
AI服务通常要求高可用,需要具备故障自动恢复机制。
服务网格为LLM系统带来的优势
- 流量管理:智能请求路由、负载均衡和流量分割能力。
- 服务发现:自动发现新部署的服务实例,实现无缝扩展。
- 健康检查:主动监测服务健康状态,及时移除不健康实例。
- 熔断与限流:防止系统过载,确保整体系统稳定性。
- 故障注入:模拟故障场景,测试系统恢复能力。
- 可观测性:提供详细的指标、日志和分布式追踪能力。
- 安全通信:服务间加密通信和身份认证。
- 策略执行:集中管理访问控制和安全策略。
微服务化LLM系统的服务网格架构设计

图2: 基于Istio的服务网格架构详细组件图
微服务化LLM系统架构层次
| 架构层 | 组件 | 功能描述 |
|---|---|---|
| 应用层 |
• 用户界面 • API网关 |
负责与用户交互,接收请求并返回结果 |
| 逻辑层 |
• 业务编排服务 • 上下文处理 • 结果整合 |
处理业务逻辑,协调各服务之间的调用 |
| 服务层 |
• LLM推理服务 • 向量存储服务 • 文档处理服务 • 缓存服务 |
提供核心功能模块,各自负责特定功能 |
| 数据层 |
• 向量数据库 • 关系型数据库 • 对象存储 |
负责数据的持久化存储和检索 |
| 服务网格层 |
• 边车代理 • 控制平面 • 网格网关 |
管理服务通信、路由、安全和可观测性 |
| 基础设施层 |
• Kubernetes • 多云资源 • GPU资源池 |
提供计算、存储和网络资源 |
多云混合部署架构设计
在多云混合部署环境中,服务网格架构可以跨越不同的云服务提供商和私有数据中心,实现统一的服务管理和通信:
- 统一控制平面:单一控制平面可以管理分布在多个云环境的服务实例
- 多集群连接:通过网格网关实现不同Kubernetes集群间的安全通信
- 全局负载均衡:根据地理位置、延迟和成本进行智能流量分配
- 统一安全策略:跨云环境实施一致的安全和访问控制策略
多云部署的关键考量因素
| 延迟敏感性 | 将需要低延迟的服务部署在地理位置接近用户的区域 |
| 资源需求 | 根据不同服务的资源需求选择合适的云服务商 |
| 容灾备份 | 跨云服务商部署备份确保高可用性 |
| 成本优化 | 利用不同云服务商的价格差异优化成本 |
| 数据主权 | 确保数据存储和处理符合各地区法规要求 |
LLM服务弹性集群架构
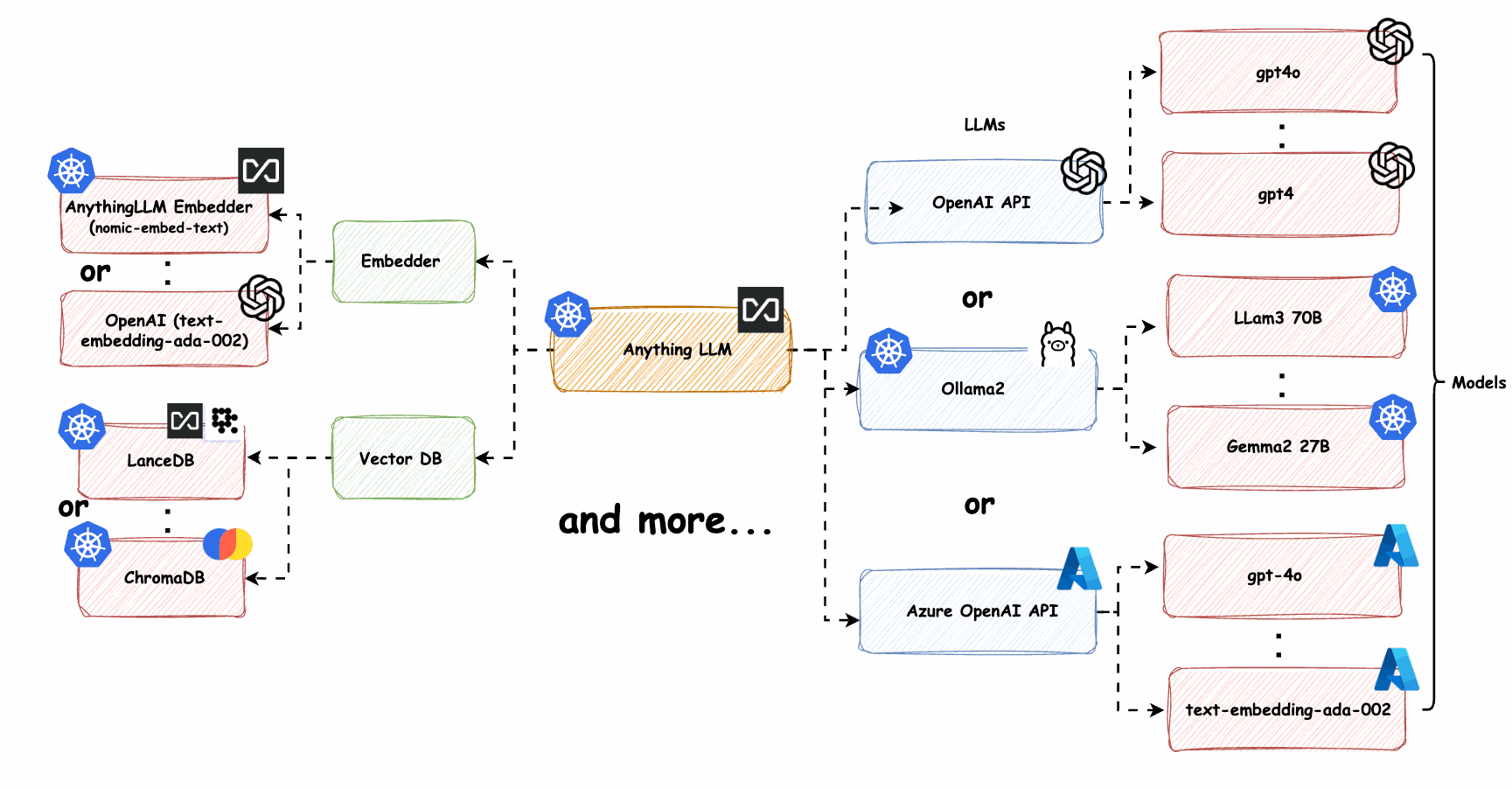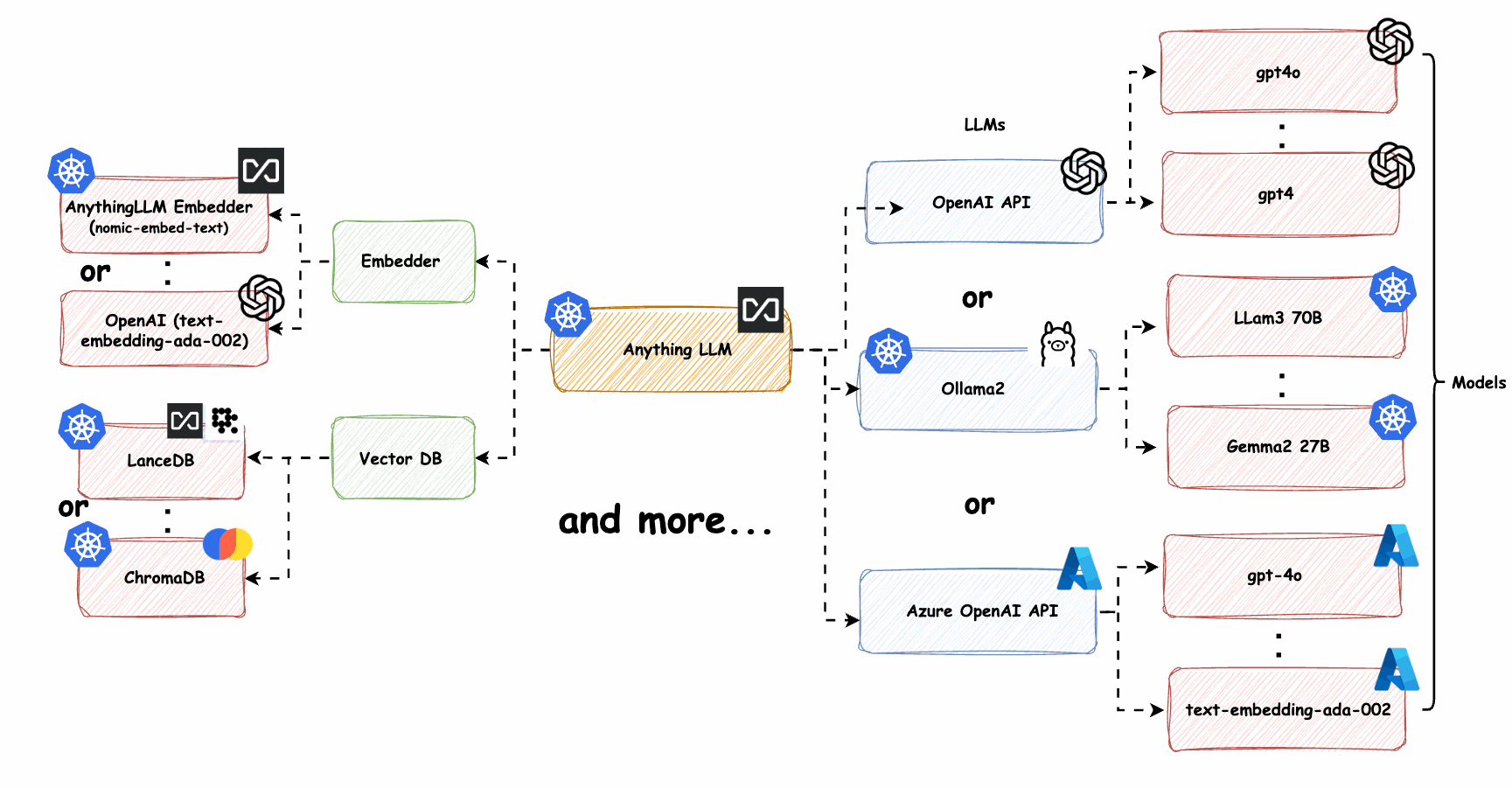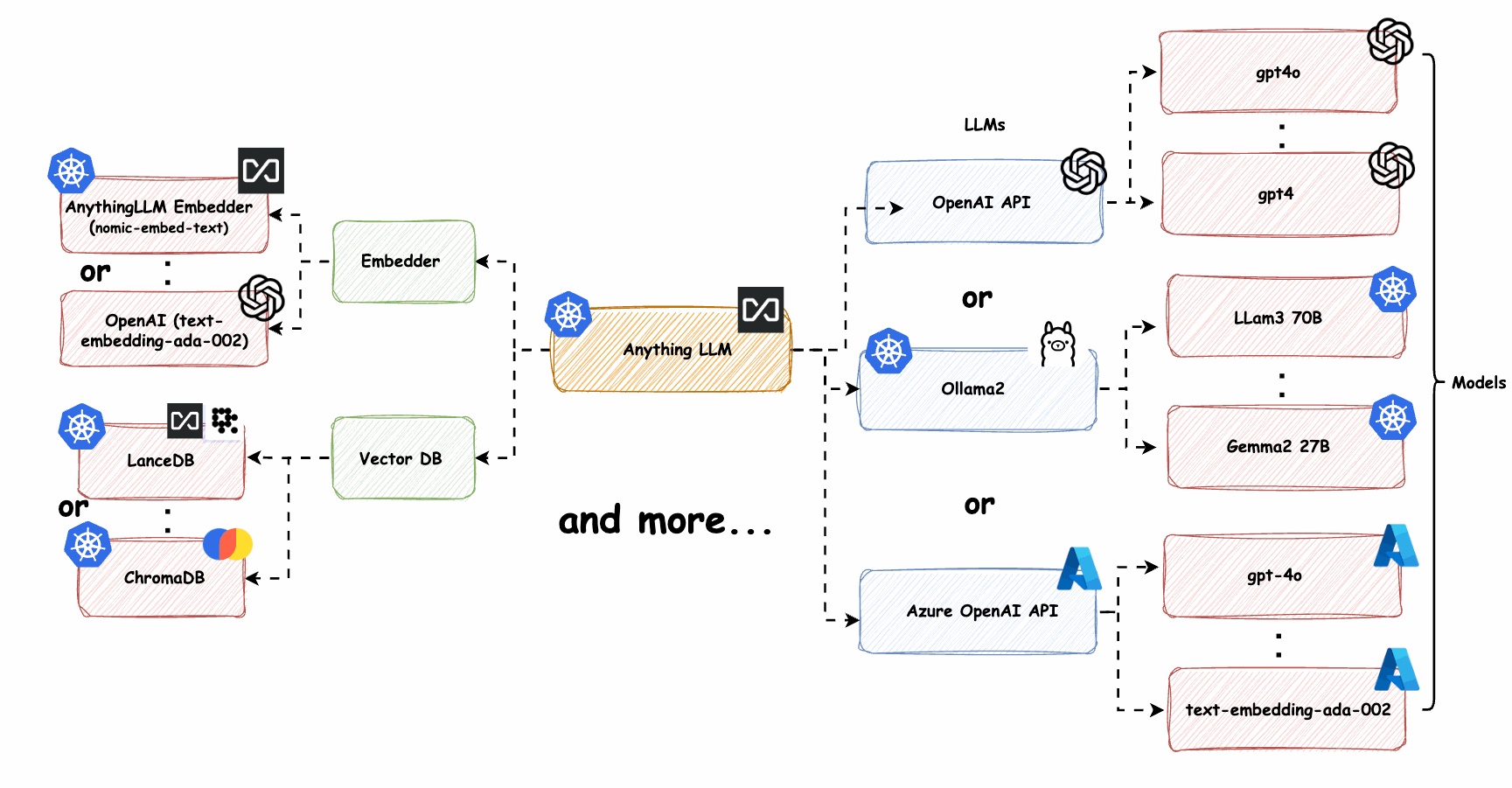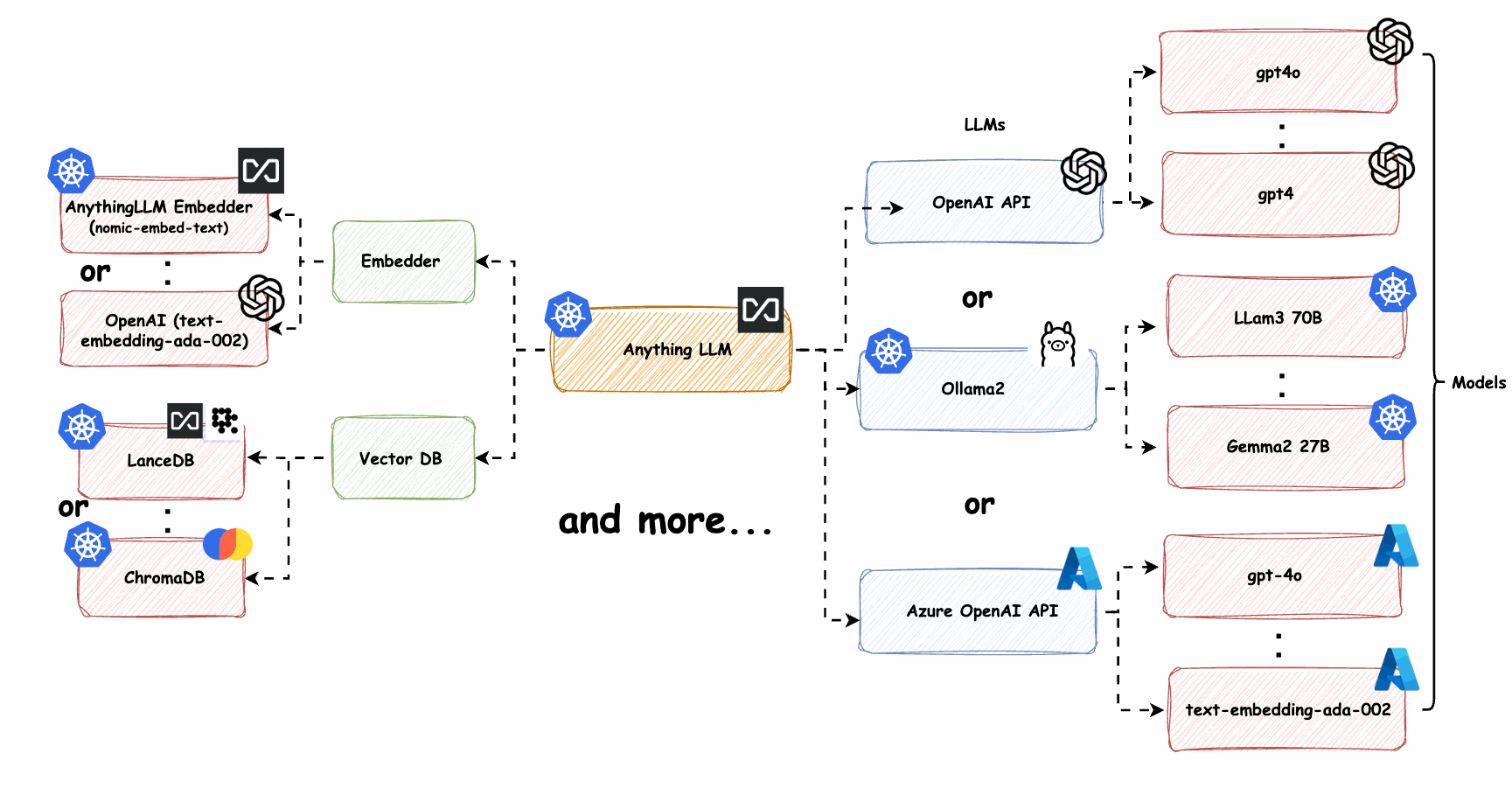
图3: Kubernetes上的LLM服务弹性集群部署
自动扩缩容
基于CPU/GPU利用率、请求队列长度或自定义指标自动调整服务实例数量,确保资源高效利用。
异构计算
混合使用GPU、CPU和专用AI加速器,根据不同模型和任务特性选择最适合的计算资源。
模型分片
将大型LLM模型拆分到多个计算节点上,实现并行计算和更高效的资源利用。
技术实现
请求路由与负载均衡
智能路由策略
在LLM系统中,不同类型的请求可能需要不同的处理方式。服务网格可以根据请求特征进行智能路由:
- 基于内容路由:根据请求内容大小、复杂度路由到不同能力的模型服务
- 基于请求优先级:高优先级请求路由到专用资源池,确保SLA
- 基于用户属性:不同级别用户可路由到不同性能等级的服务
- 基于A/B测试:将部分流量路由到新版本LLM模型进行验证
Istio配置示例 - 基于请求内容长度路由:
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: llm-routing
spec:
hosts:
- llm-service
http:
- match:
- headers:
content-length:
exact: "large"
route:
- destination:
host: llm-service-high-capacity
subset: large-model
- route:
- destination:
host: llm-service-standard
subset: default
LLM服务负载均衡策略
传统的轮询或随机负载均衡策略可能不适合LLM服务的特点,服务网格提供了更智能的负载均衡能力:
| 负载均衡策略 | 适用场景 | 优势 |
|---|---|---|
| 基于GPU利用率 | 推理计算密集型任务 | 最大化GPU资源利用效率 |
| 最短队列优先 | 处理时间不确定的请求 | 降低平均等待时间 |
| 令牌桶限流 | 需要精确控制QPS的场景 | 防止服务过载,平滑流量峰值 |
| 会话亲和性 | 有状态多轮对话 | 提高上下文处理效率 |
| KV缓存感知 | 大型模型推理 | 充分利用缓存提高推理性能 |
实现提示:
针对LLM特点的负载均衡通常需要实现自定义的负载均衡算法。可通过Istio的EnvoyFilter或自定义资源扩展实现基于GPU利用率和KV缓存状态的负载均衡。
降级策略与容灾管理
LLM系统降级策略
当LLM服务面临高负载或部分故障时,可实施以下降级策略:
-
模型降级:从高性能大模型切换到轻量级模型
- 例:从175B参数模型回退到7B参数模型
-
功能降级:关闭非核心功能,保证核心服务可用
- 例:暂时关闭插件、多模态功能
-
精度降级:降低模型精度,提高处理速度
- 例:从FP32切换到INT8量化模型
-
缓存响应:对于非个性化请求,返回缓存结果
- 例:热门问题直接返回预计算结果
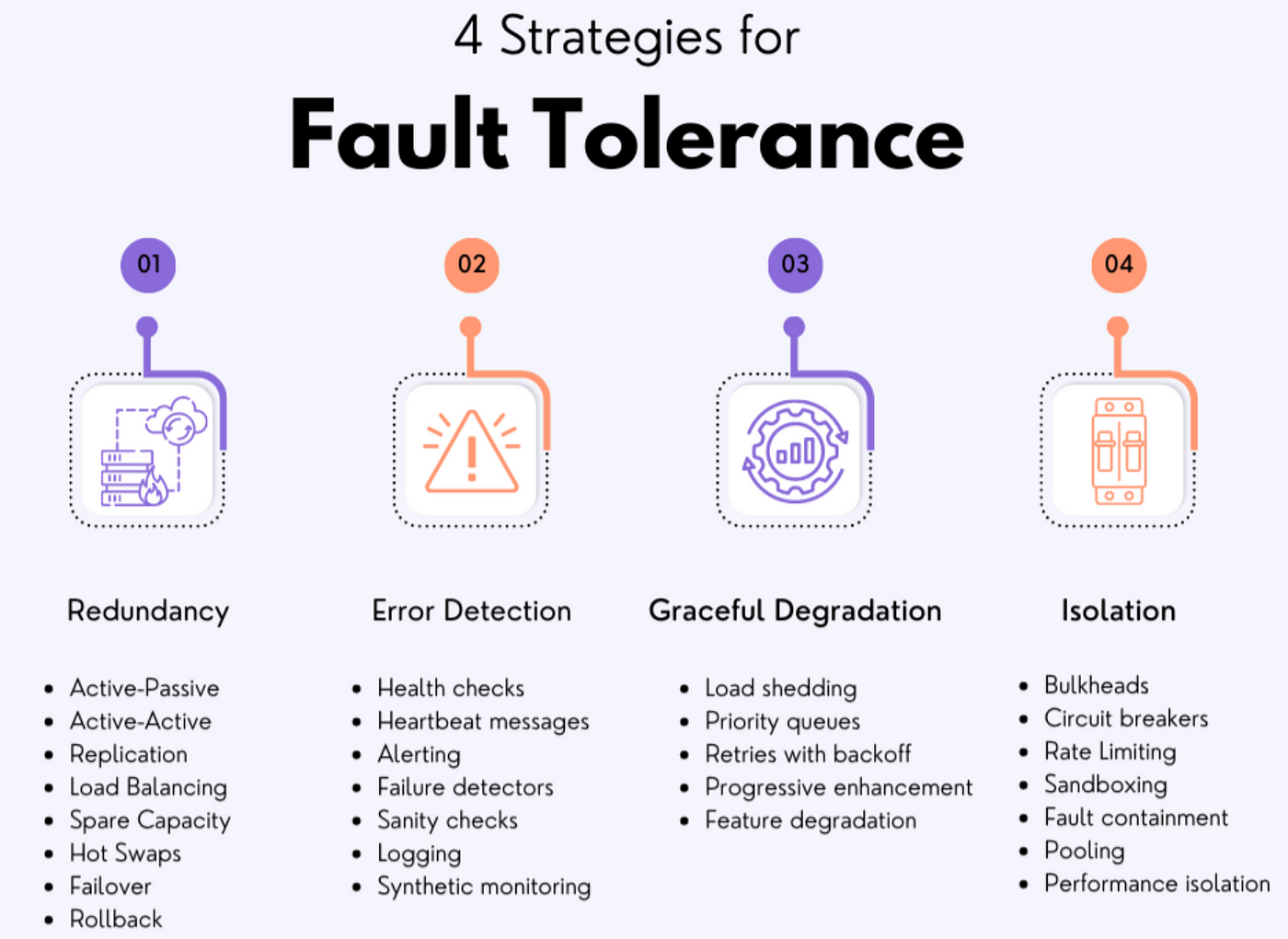
图4: 故障容错系统的层次结构
容灾与故障恢复
构建多层次容灾架构,确保系统在各种故障场景下的韧性:
| 容灾级别 | 实现方式 | 恢复目标 |
|---|---|---|
| 服务级 | 服务熔断、自动重试、流量转移 | 秒级恢复 |
| 节点级 | Pod自愈、健康检查、副本集 | 分钟级恢复 |
| 可用区级 | 多可用区部署、区域亲和性 | 自动容灾 |
| 区域级 | 多区域部署、全球负载均衡 | RPO/RTO较低 |
| 多云级 | 跨云服务商部署、数据同步 | 极端灾难恢复 |
LLM服务的故障转移策略
多级备份:
- 首先尝试使用相同模型的其他实例
- 如果同模型实例均不可用,转向备用模型
- 如果当前区域服务不可用,转向其他区域
- 如果自有基础设施不可用,转向云服务商提供的托管LLM服务
故障检测:
通过主动健康检查、延迟监控、错误率统计等多维度指标检测服务状态,结合机器学习预测性地发现潜在故障。
LLM服务的优雅降级实现示例
# 使用Istio的故障注入和重试策略实现LLM服务的优雅降级
apiVersion: networking.istio.io/v1alpha3
kind: VirtualService
metadata:
name: llm-service-resilient
spec:
hosts:
- llm-service
http:
# 主路由 - 高性能模型
- name: "primary-model"
route:
- destination:
host: llm-service-premium
subset: v1
weight: 100
timeout: 5s
retries:
attempts: 2
perTryTimeout: 2s
retryOn: gateway-error,connect-failure,refused-stream
# 如果主模型服务失败,降级到备用模型
fault:
abort:
percentage:
value: 100
httpStatus: 500
fallback:
destination:
host: llm-service-standard
subset: v1
# 监控指标,如果错误率超过阈值,触发断路器
circuitBreaker:
thresholdPercentage: 50
minimumRps: 10
rollingWindowDuration: 60s
consecutiveErrors: 5
interval: 1s
baseEjectionTime: 30s
多云混合部署实现
多云网格连接策略
跨云服务网格部署需要解决以下挑战:
- 网络连通性:通过安全隧道实现跨云网络连接
- 服务发现:全局服务注册与发现机制
- 证书管理:跨云统一的证书颁发与验证
- 流量管理:考虑跨云网络延迟的智能路由
多云服务网格架构方案:
- 共享控制平面模式:单一Istio控制平面管理多个集群
- 多控制平面模式:每个云有独立控制平面,通过网关互联
- 分层控制平面:主控制平面协调多个子控制平面,适合大规模部署
资源调度策略
有效的跨云资源调度是多云混合部署的核心:
| 调度策略 | 适用场景 |
|---|---|
| 成本优先 | 批量处理任务,对延迟不敏感 |
| 性能优先 | 实时交互应用,需低延迟 |
| 本地化优先 | 数据主权要求高的场景 |
| 动态混合 | 根据实时情况调整部署策略 |
多云统一监控
跨云环境需要统一的可观测性平台,以提供:
- 端到端请求追踪
- 跨云资源利用率监控
- 统一的告警与事件管理
- 全局性能分析与瓶颈识别
案例:混合云LLM服务部署架构
假设企业需要在AWS、Azure和私有数据中心部署LLM服务,可采用以下架构:
- 控制层:Istio控制平面部署在私有数据中心主集群
- 数据层:敏感数据存储在私有数据中心,普通数据可分散存储在云端
- 推理层:
- 高峰时段:充分利用云平台GPU资源弹性扩展
- 常规负载:主要使用私有数据中心资源
- 备用容灾:云平台作为灾备,保持最小规模部署
- 入口层:全球CDN结合地理DNS,将用户请求路由到最近的入口点
注:该架构依靠服务网格提供的统一服务发现、安全通信和流量管理能力,实现跨环境的无缝服务体验。
最佳实践
性能优化
服务网格性能调优
服务网格虽然提供了丰富的功能,但也引入了额外的开销,需要特别注意性能优化:
- 精细化控制代理资源:为Sidecar代理分配合适的CPU和内存资源
- 选择性启用功能:只启用必要的服务网格功能,如传输加密
- 优化遥测数据采集:调整采样率,避免过度收集
- 网络策略调优:优化重试机制,避免请求风暴
- 缓存配置优化:为Sidecar代理配置合理的缓存策略
LLM服务性能优化
LLM服务性能优化需要从多个层面考虑:
- 模型优化:量化、蒸馏、稀疏化等技术减少模型大小和计算量
- 推理加速:使用vLLM、TensorRT等优化推理引擎
- KV缓存优化:高效管理Attention缓存,提高长文本处理性能
- 批处理优化:动态批处理策略,提高GPU利用率
- 预热与缓存:常用模型预加载,热点查询结果缓存
提示:在服务网格环境中,合理设置超时时间和请求大小限制,避免长尾请求占用过多资源。
监控与可观测性
在分布式LLM服务系统中,建立全方位、多层次的可观测性体系至关重要:
指标监控
- 系统指标:CPU/GPU利用率、内存使用、网络IO
- 服务指标:请求QPS、延迟分布、错误率
- LLM特有指标:Token吞吐量、批处理效率
- 业务指标:回答质量评分、用户满意度
链路追踪
- 端到端追踪:从请求到响应完整链路
- 跨服务追踪:微服务间调用关系可视化
- LLM处理阶段:提示处理、推理、后处理各阶段时间
- 瓶颈识别:标识处理流程中的慢操作
日志管理
- 结构化日志:统一日志格式,便于分析
- 关联ID:通过请求ID关联分布式日志
- 采样策略:对常见请求进行采样,降低存储压力
- 异常与错误:详细记录异常信息和堆栈
LLM系统特有的可观测性
模型性能监控
- • 推理延迟(首token/后续token)
- • 模型吞吐量(tokens/second)
- • GPU内存利用率、计算效率
- • KV缓存命中率和效率
- • 批处理效率和动态批大小
质量与业务指标
- • 回答准确率和相关性评分
- • 幻觉检测率和类型统计
- • 用户反馈和满意度指标
- • 提示质量评估
- • 安全风险监测(有害内容、隐私泄露)
可观测性最佳实践:
搭建统一的可观测性平台,结合服务网格原生的遥测能力和LLM专用监控工具。例如,使用Prometheus、Grafana监控系统指标,Jaeger追踪请求,ELK/Loki管理日志,LangSmith等工具监控LLM质量指标,通过告警系统实现自动化运维响应。
安全与合规
LLM系统处理的数据通常包含敏感信息,需要全方位的安全保障:
服务网格安全能力
| 安全功能 | 实现方式 |
|---|---|
| mTLS加密 | 服务间通信自动加密,防止数据窃听 |
| 身份验证 | 基于服务身份的认证,整合SPIFFE/SPIRE |
| 授权策略 | 细粒度访问控制,基于角色和属性的授权 |
| 安全审计 | 全面记录访问日志和安全事件 |
| 证书管理 | 自动化的证书轮换和管理 |
LLM特有安全考量
- 提示注入防护:检测和过滤恶意提示,防止模型操纵
- 数据隐私保护:确保用户数据不被不当使用或泄露
- 输出内容审核:过滤有害、违规或敏感信息
- 模型权限隔离:基于多租户的模型访问控制
- 服务调用风险管控:限制LLM访问外部服务的能力和范围
多租户隔离策略
在共享LLM服务环境中,通过以下方式实现租户隔离:
- 命名空间隔离:不同租户使用独立Kubernetes命名空间
- 网络策略:通过服务网格实现细粒度流量控制
- 资源配额:为各租户分配专用资源池
- 数据隔离:确保租户数据严格分离存储和处理
架构演进路线
第一阶段
基础服务网格
- 单集群Istio部署
- 基本流量管理
- 简单的故障恢复
- 单一云环境
第二阶段
高级流量管理
- 智能路由策略
- 自定义负载均衡
- 熔断与限流
- 多级降级策略
第三阶段
多集群扩展
- 跨集群服务发现
- 区域级故障转移
- 高级安全策略
- 全面可观测性
第四阶段
多云混合架构
- 跨云服务网格
- 全球负载均衡
- 自适应资源调度
- 自动化运维
规划建议
从现有架构向服务网格架构演进时,建议采取渐进式方法:
- 1. 评估与准备 - 全面评估现有系统和业务需求,制定详细迁移计划
- 2. 试点验证 - 选择非核心服务进行小规模试点,验证技术可行性
- 3. 基础设施升级 - 升级Kubernetes集群,确保支持服务网格所需资源
- 4. 分阶段迁移 - 按照服务重要性和依赖关系逐步迁移应用到服务网格
- 5. 能力扩展 - 在基础功能稳定后,逐步启用高级特性和多云支持
- 6. 持续优化 - 基于实际运行数据不断优化架构和配置
行业案例与总结
行业应用案例
金融服务行业
某大型银行构建了基于服务网格的LLM平台,用于智能客服和金融顾问。
- 严格的合规与安全要求
- 高可用性要求(99.99%)
- 敏感数据处理的隐私保护
- 采用多层安全架构,所有服务间通信强制mTLS
- 实施细粒度访问控制和审计日志
- 构建混合云部署,敏感数据严格限制在私有数据中心
- 五层降级策略确保核心服务永远可用
电子商务平台
全球性电子商务平台构建LLM微服务生态,实现全渠道客户体验提升。
- 全球分布式部署需求
- 季节性流量波动巨大
- 多语言多地区服务
- 跨六个区域的多云部署,就近服务原则
- 基于预测的弹性扩缩容策略
- 区域特定模型与全球共享模型结合
- 全球网格网关确保跨区域低延迟通信
"服务网格为我们的LLM系统提供了前所未有的弹性和可观测性。在一次区域性网络故障中,系统自动完成了跨区域流量迁移,用户几乎没有感知到任何中断。"
技术展望
智能网格与AI
服务网格本身也在融入AI技术,通过机器学习实现自适应路由、智能负载预测和自动故障预防。未来的LLM微服务架构将受益于这些"智能网格"技术。
边缘计算集成
服务网格正在向边缘扩展,使LLM服务能够更接近用户部署。这将降低延迟,提高性能,同时保持集中管理和安全控制的能力。
平台无关网格
跨平台服务网格标准正在发展,未来将实现更无缝的多云和混合云部署,使LLM服务能够真正实现"部署一次,随处运行"的愿景。
总结
服务网格架构为微服务化LLM系统提供了强大的基础设施支持,通过统一的流量管理、安全控制和可观测性能力,解决了复杂分布式系统面临的诸多挑战。在多云混合部署场景中,服务网格尤其能发挥其价值,帮助企业构建高弹性、高可用的LLM服务集群。
随着LLM技术和服务网格技术的不断发展,两者的结合将创造出更智能、更可靠、更高效的AI服务架构,为企业数字化转型提供强有力的技术支撑。